
Künstliche Kommunikation: Workshop Hinter den Kulissen von ChatGPT & Co.
1. Ein Sprachmodell von aussen betrachtet I
Wir verwenden im Kurs folgende Begriffe mehr oder weniger synonym:
Sprachmodell, Large Language Modell, LLM, Transformer, Transformer Modell.
2. Ein Sprachmodell von aussen betrachtet II
Um zu verstehen, was bei einem Sprachmodell „hinter den Kulissen“ passiert, müssen wir uns zunächst die Aussenseite genauer anschauen.
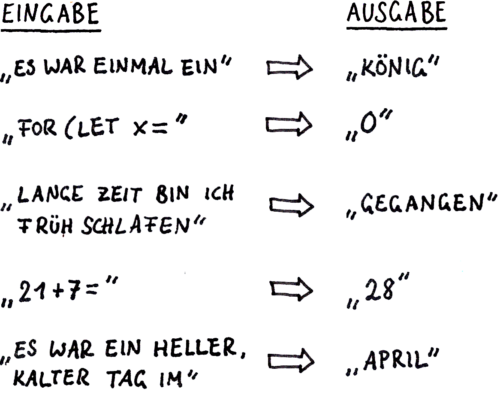
Die grundlegende Leistung von Sprachmodellen besteht darin, zu einem gegebenen Textfragment (Eingabe) das jeweils nächste Wort zu ermitteln.
Das gefundene Wort wird an die vorherige Eingabe angehängt. Auf diese Weise entsteht, Wort für Wort, ein kompletter Text.
Eigentlich arbeiten Sprachmodelle in der Regel nicht mit Wörtern, sondern mit Token. Dazu später mehr!
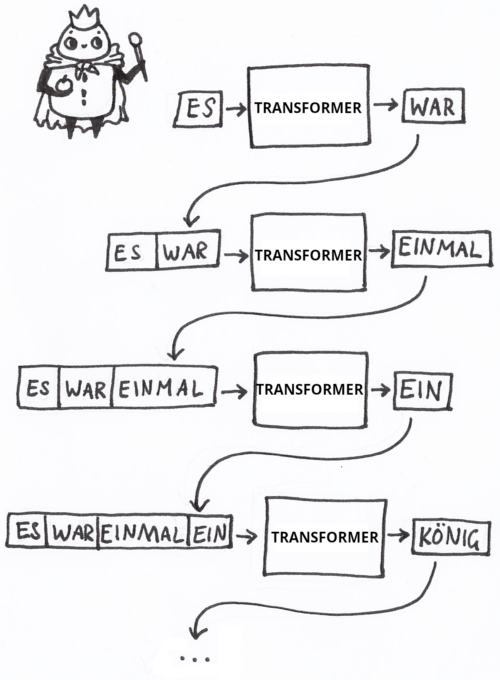
Genauer betrachtet, gibt das Sprachmodell nicht ein Wort heraus, sondern eine Liste mit Wahrscheinlichkeiten für jedes einzelne Wort im Vokabular.
Angenommen, unser Vokabular besteht nur aus 6 Wörtern, dann könnte eine solche Liste so aussehen:

Damit ist bereits geklärt, was an der Ausgabeseite des Sprachmodells passiert. Unklar bleibt:
Frage 1: Wie wird die Eingabe (der bisherige Text) in etwas verwandelt, womit eine KI (ein neuronales Netz) rechnen kann?
Frage 2: Wie kommt die Ausgabe aufgrund der jeweiligen Eingabe zustande?
Letztlich läuft es darauf hinaus: Wenn wir Frage 1 beantwortet haben, dann ist damit auch Frage 2 beantwortet!
3. Ein Künstliches Neuronales Netz, das Ziffern erkennt
Die Verarbeitung von Sprache in Künstlichen Neuronalen Netzen (KNN) ist eine sehr abstrakte Angelegenheit. Wir werden uns bei mehreren Gegelenheiten KNNs anschauen, die visuelle Signale verarbeiteten. Diese sind – u.a. weil besser grafisch darstellbar – leichter nachvollziehbar. Das dabei gewonnene Verständnis lässt sich dann auf KNNs übertragen, die Sprache verarbeiten.
Auch in diesem Beispiel ist klar, was an der Ausgabeseite passiert: Das KNN zur Zeichenerkennung liefert eine Liste, die für jedes in Frage kommende Zeichen eine Wahrscheinlichkeit zwischen 0 und 1 angibt. Es funktioniert übrigens nicht besonders gut, gibt aber eine Zahlenliste aus, das war mir an dieser Stelle wichtig 😉
Wie das Bild in das KNN hineingelangt, zeigt das folgende Bild. Hier ist das Bild auf der Eingabeseite 3 x 3 Pixel groß. Also hat das KNN auf der Eingabeseite 9 Neuronen, eines für jedes Pixel. Da hier nur drei Zeichen unterschieden werden sollen, besteht die Ausgabeschicht aus drei Neuronen:

Hier ist die entscheidende Frage, noch einmal: Was passiert zwischen Eingabe- und Ausgabeseite? Wie berechnet das Netz die Ausgabe?
Wir können auf diese Frage hier nicht im Detail eingehen, und müssen uns mit einer kurzen Beschreibung begnügen. Die Mathematikerin Hannah Fry schreibt in ihrem Buch „Hello World“ (München 2019):
Ein künstliches neuronales Netz kann man sich als eine riesige mathematische Struktur vorstellen, mit jeder Menge Schaltern und Reglern. Man speist ein Bild an einem Ende ein, es fließt durch eine Struktur, und am anderen Ende kommt eine Vermutung heraus, was dieses Bild enthält. Eine Wahrscheinlichkeit für jede Kategorie: Hund oder nicht Hund.
Die Schalter und Regler bestimmen das Ergebnis.
Wie werden die Schalter und Regler eingestellt?
Hier kommt das sogenannte Überwachte Lernen zum Zuge. Wie das funktioniert, skizzieren die folgenden Abbildungen anhand der Aufgabe, Bilder danach zu klassifizieren, ob sie einen Hund oder eine Katze abbilden.
Zunächst werden Trainingsdaten benötigt. Das sind im gegeben Beispiel Bilder von Hunden und Katzen, verknüpft mit der jeweils richtigen Ausgabe:
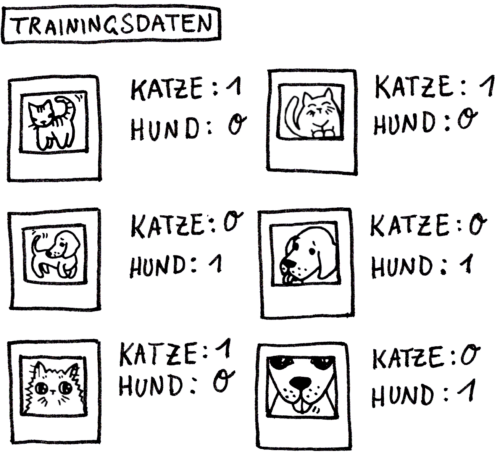
Das Lernen (= Training) läuft dann wie folgt ab: Die „Schalter und Regler“ sind zunächst mit zufälligen Werten initialisiert. Entsprechend „rät“ das KNN. Der Vergleich zwischen der bekannten korrekten Ausgabe und der tatsächlichen Ausgabe ergibt einen Fehler. Dieser wird genutzt, um das KNN nachzujustieren, damit es beim nächsten Mal etwas weniger falsch liegt:
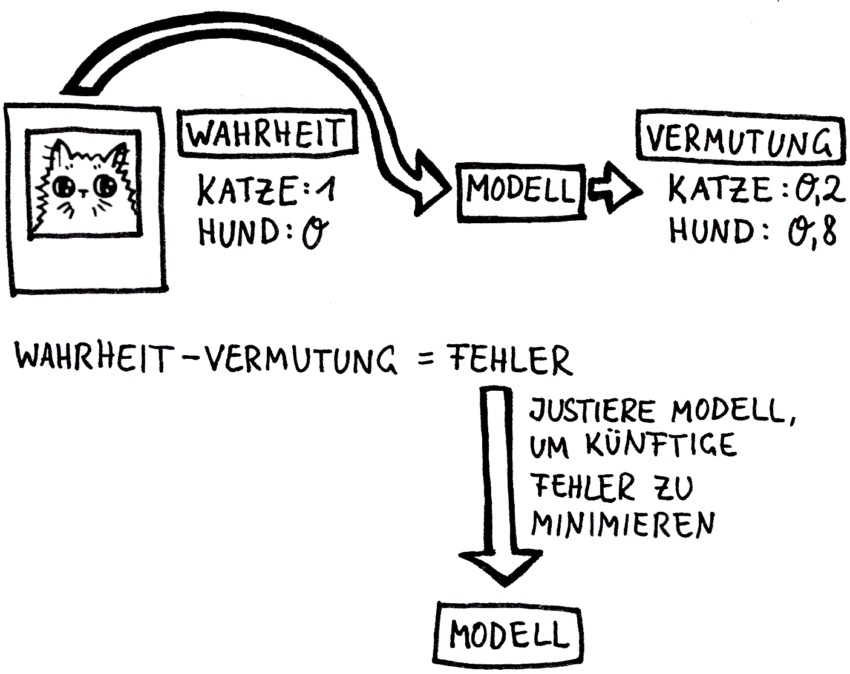
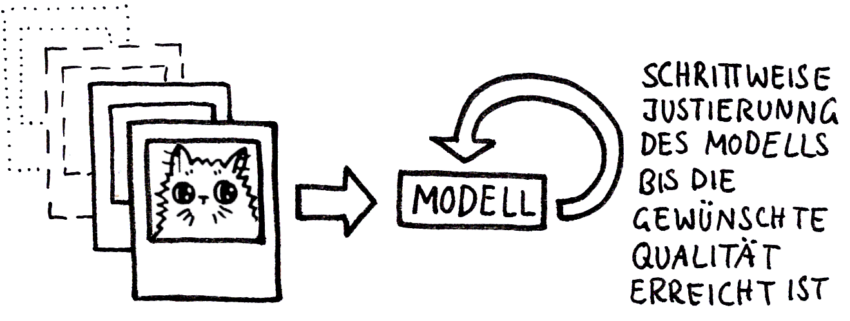
Dieser Prozess wird so oft wiederholt, bis die gewünschte Qualität erreicht ist:
4. Was ist ein Datenpunkt
Der nächste Schritt zum Verständnis großer Sprachmodelle besteht darin, zu verstehen, was ein Datenpunkt ist.
Wenn eine Lebensmittelanalyse Werte für Fett- und Zuckergehalt sammelt, kann jedes einzelne Ergebnis als ein Datenpunkt in einem Raum mit zwei Dimensionen betrachtet werden. Dieses Prinzip lässt sich auf beliebig viele Dimensionen erweitern. Wenn also noch der Gehalt an Kohlenhydraten, Salz und Eiweißen gemessen wird, könnte jede Messung durch einen Datenpunkt im fünfdimensionalen Raum dargestellt werden.
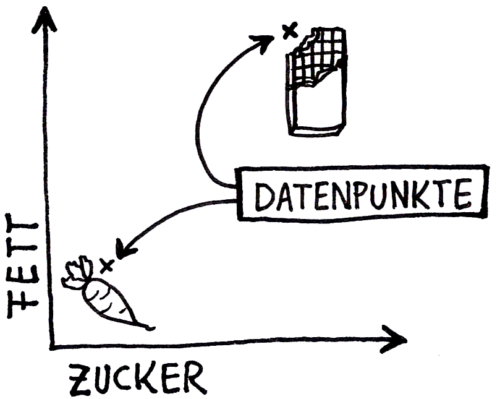
Zwei Lebensmittel, die durch ihren Fett- und Zuckergehalt in einem zweidimensionalen Raum repräsentiert werden.

Über die räumliche Nähe von Datenpunkten lassen sich Ähnlichkeiten bzw. Klassen wie Süßwaren und Gemüse identifizieren.
Auch wenn es auf den ersten Blick befremdlich erscheinen mag: Es ergibt sehr viel Sinn, ein Bild, das aus 9 Pixeln besteht, als einen Datenpunkt in einem 9-dimensionalen Raum zu betrachten!
Begriffsklärung: Wir haben vorhin von Listen gesprochen, die für jede erkannte Bild- oder Zeichenklasse eine Wahrscheinlichkeit enthalten. Jetzt ist die Rede von Datenpunkten. Auch das sind eigentlich Listen von Werten, in diesem Fall Koordinaten. Mathematisch betrachtet gibt es keinen Unterschied zwischen diesen Listen und Datenpunkten. Der übergeordnete Begriff, den wir ab jetzt auch verwenden werden, lautet Vektor. Hierbei unterscheiden wir jedoch zwischen Ortsvektoren, die einen Punkt im Raum beschreiben, und Relationsvektoren, die eine Verschiebung oder Relation zwischen zwei Punkten darstellen.
5. Wie wird aus einer Texteingabe ein Datenpunkt?
Wir wissen nun, wie wir Messwerte (Zucker und Fettgehalt…) oder ein Bild (3×3 Pixel) in einen Datenpunkt überführen können, ist nunmehr klar.
Wie aber können wir eine Texteingabe in einen Datenpunkt übersetzen?
Dazu müssen wir in mehreren Schritten vorgehen:
5.1 Wie wird aus einem Wort ein Datenpunkt?
Die Übersetzung von Wörtern in Datenpunkte leisten sogenannte Worteinbettungen.
Die folgenden Bilder illustrieren, was eine Worteinbettung leistet:

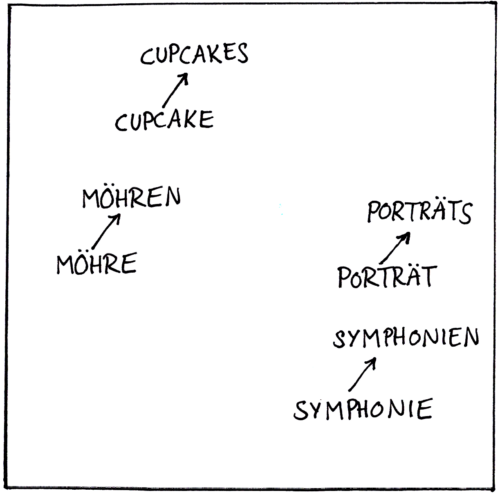
Worteinbettungen ordnen Wörter so in einem hochdimensionalen Raum an (hier aus Gründen der Darstellbarkeit ist der Raum lediglich zweidimensional), dass folgendes gilt:
- Wörter, die ähnliches bezeichnen, stehen dicht beieinander
- Semantische (die Bedeutung betreffend) und syntaktische (Satzbau und Grammatik betreffend) Beziehungen zwischen Wörtern werden in Vektoren übersetzt.
Wie gelangen wir zu solch praktischen Anordnungen? Sie werden anhand von sehr großen Textmengen gelernt.
Wie das genau funktioniert, können wir im Rahmen dieses Workshops nur kurz skizzieren.
In einem sehr überschaubaren, selbstgeschriebenen Beispielprogramm haben wir mit einer generierten Menge von Sätzen gearbeitet, die alle nach dem selben Muster aufgebaut sind:
- ein koch kocht jetzt schonend die soße
- zwei musikfreunde proben gerade pfeifend den song
- fünf diebinnen raubten letztens dreist einen tresor
- ein autor textet gerade hochkonzentriert ein anschreiben
- zwei köche kochen gerade schonend die soße
- eine diebin raubt jetzt rücksichtslos den geldkoffer
- ein autor schrieb neulich wortgewandt eine kurzgeschichte
Also
- Artikel (ein, zwei, fünf…)
- Subjekt (koch, musikfreunde, diebinnen)
- Prädikat (kocht, proben, raubten)
- Adverbiale Bestimmung der Zeit (jetzt, gerade, letztens)
- Adverbiale Bestimmung der Art und Weise (schonend, pfeifend, dreist)
- Objekt (die soße, den song, einen tresor)
Schritt I
Ein „Kontextfenster“ wandert über alle Sätze, und stellt Zuordnungen zwischen Zielwort und Kontextwort her:
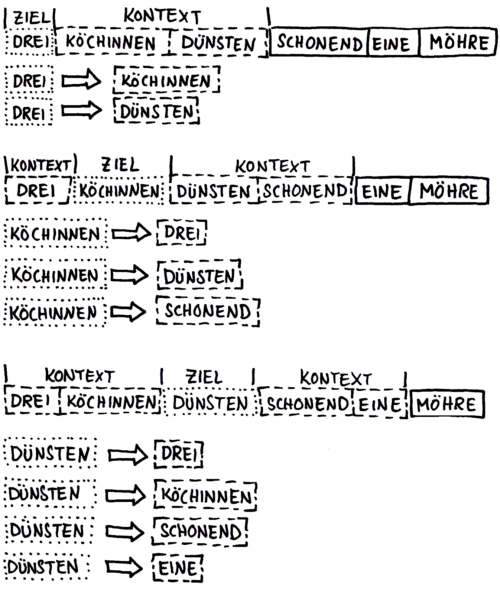
Schritt II
Das Ergebnis sind unsere Trainingsdaten (Die Wörter sind hier One-Hot-Codiert):
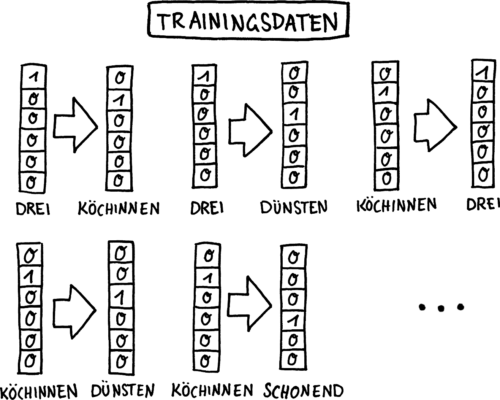
Schritt III
Ein KNN zur Berechnung der Zuordnungen zwischen Ziel- und Kontextwort wird konstruiert:
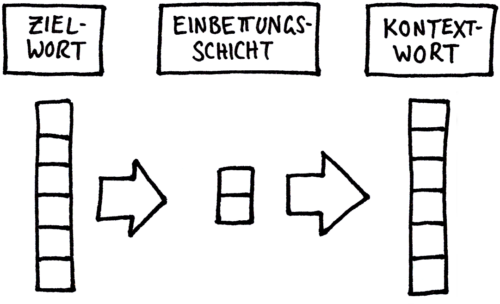
Schritt IV
Da die Zuordnungen nicht eindeutig sind, gibt das KNN Wahrscheinlichkeiten aus!
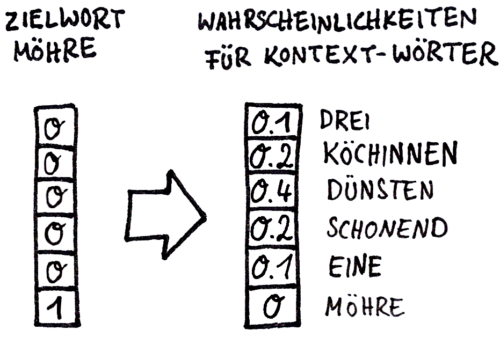
Nachdem das Training abgeschlossen ist, wird die Ausgangsschicht entfernt!
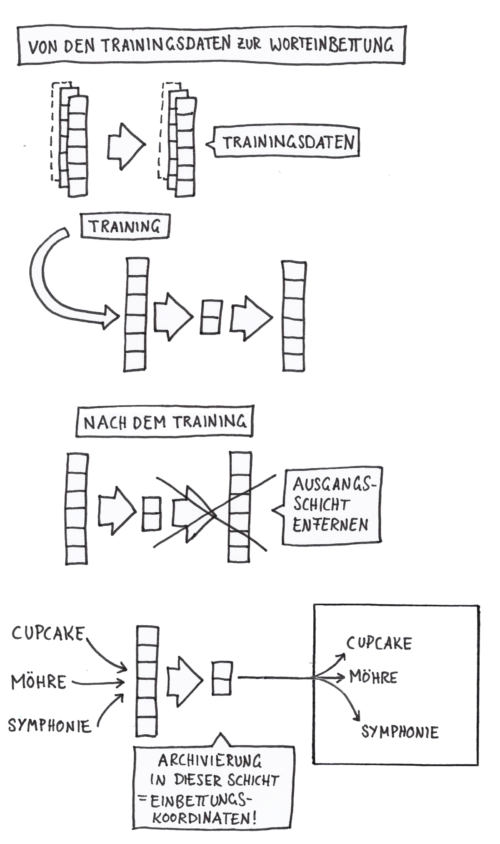
(Weitere Erklärungen siehe „Künstliche Intelligenz verstehen“ ab Seite 288)
■ Link: Beispielprogramm Wort-Navigator
Dieses Bild zeigt, was der Sequenz-Navigator macht:
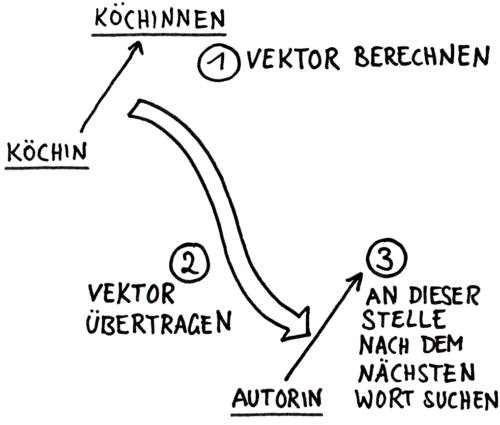
5.2 Wie wird aus einem Text ein Datenpunkt?
Das folgende Bild zeigt eine sehr einfache Methode, aus einem Satz einen Datenpunkt (= einen Vektor) zu berechnen:
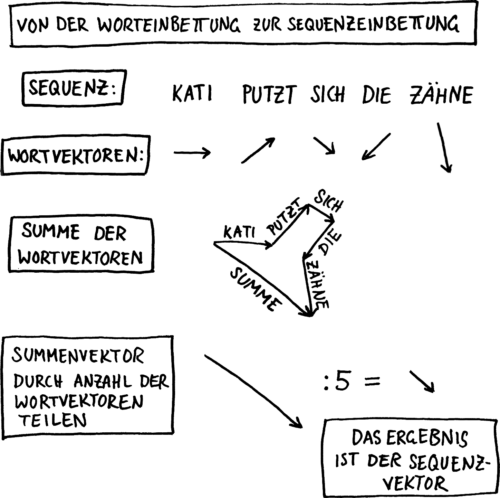
Der Haken dieser Methode liegt auf der Hand: Die Reihenfolge der einzelnen Wörter spielt keine Rolle. Mann beißt Hund und Hund beißt Mann ergeben den selben Vektor.
Trotzdem ist diese Methode erstaunlich leistungsfähig. Das haben wir wiederum anhand eines selbstgeschriebenen Beispielprogramms ausprobiert, das auf „konstruierten“ Texten basiert.
Die Texte schildern Tagesabläufe von Kati Katzenstein. Kati lebt allein, arbeitet in einer Gärtnerei, legt Wert auf eine abwechslungsreiche Ernährung, hat viele Hobbys und tendiert in modischen Fragen zu gewagten Kombinationen.
Katis Tage laufen immer nach dem gleichen Schema ab und durchlaufen folgende Stationen: aufwachen, aufstehen, Frühstück, Zähne putzen, ankleiden, Weg zur Arbeit, Arbeit Vormittag, Mittagessen, Arbeit Nachmittag, Heimweg, Abendessen, ausgehen oder Sofa, schlafen gehen.
- Innerhalb dieses starren Schemas gibt es allerdings zahlreiche Variationen, etwa beim Frühstück:
- Danach macht Katharina sich ein schnelles Frühstück, und zwar gibt es ein Croissant und ein Glas Orangensaft.
- Sodann macht unsere Heldin sich Frühstück, und zwar ein Käsebrötchen und einen Becher Kaffee.
- Anschließend macht Kati sich ein Frühstück, und zwar eine Schale Müsli und einen Apfelsaft.
Es zeigt sich, dass Datenpunkte (= Vektoren), die sich auf gleiche Tagesstationen beziehen, in der Einbettung Gruppen (= Cluster) bilden:
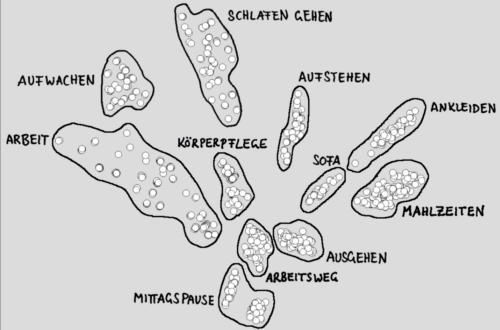
(Weitere Erklärungen siehe „Künstliche Intelligenz verstehen“ ab Seite 291)
■ Link: Beispielprogramm Sequenz-Navigator
■ Link: Sätze, anhand derer die Einbettung gelernt wurde
6. Alles was Du brauchst, ist Aufmerksamkeit
Es ist deutlich geworden: Die eben gezeigte Methode, Texte in Vektoren umzuwandeln, ist einerseits leistungsfähiger, als der erste Blick vermuten lässt. Andererseits ist klar: Diese Methode reicht nicht, um Leistungen zu bringen, wie wir sie von ChatGPT und Co. kennen.
Dieses Bild zeigt ein weiteres Problem:

Der entscheidende Schritt, der die aktuell bestaunten Leistungen ermöglicht hat, war die Entwicklung des sogenannten Aufmerksamkeistmechanismus im Jahr 2017.
Um zu verstehen, was dahintersteckt, müssen wir wieder auf ein Beispiel zurückgreifen, das grafische Signale verarbeitet:
■ Faltungsnetz Demo
Ähnlich, wie in diesem Beispiel unterschiedliche Filterkernel spezialisiert sind, unterschiedliche Merkmale des Bildes zu erkennen, können Aufmerksamkeitsköpfe unterschiedliche Merkmale der Eingabe erkennen.
Wir stellen übrigens lediglich die Struktur bereit, mittels derer das Sprachmodell die Merkmale erlernen können. In manchen Fällen können wir mit dem Finger darauf zeigen: „Dieser Filter erkennt senkrechte Kanten“ oder „Dieser Aufmerksamkeitskopf stellt Subjekt-Objekt Zuordnungen her.“ In den meinsten Fällen aber ist die Aufgabe der einzelnen Filter bzw. Aufmerksamkeitsköpfe überhaupt nicht nachvollziehbar für menschliche Betrachter.
Wir bauen eine Struktur (ein sehr komplexes KNN, bestehend aus einer Einbettunsgschicht, mehrerer in Reihe geschalteter Aufmerksamkeitsschichten u.v.m.) mittels derer das KNN dann lernen kann, das nächste Wort vorherzusagen. Wie das KNN die Aufgabe löst, ist in der Regel nicht nachvollziehbar. Das wird allgemein als Black Box Problem bezeichnet.
So könnten übrigens Traininsdaten für ein Transformermodell aussehen:
7. Praxisteil: Hands on GPT2
01 Texte generieren, Token inspizieren